基于协同过滤算法的商品推荐系统设计与实现
一、开题报告
1.1 选题背景与意义
随着电子商务的快速发展,商品数量呈现爆炸式增长,用户面临着信息过载的困境。传统的关键词搜索和分类浏览方式已难以满足用户个性化、智能化的购物需求。推荐系统通过分析用户历史行为数据,预测其潜在兴趣,主动推送相关商品,成为解决信息过载、提升用户体验和商业转化率的关键技术。协同过滤算法作为推荐系统领域的经典和主流方法,通过发掘用户与商品之间的隐含关联,具有无需领域知识、推荐结果新颖等优势。本项目旨在设计并实现一个基于协同过滤算法的商品推荐系统,具有重要的理论探索价值和实际应用意义。
1.2 研究目标与内容
研究目标: 构建一个能够准确预测用户偏好、实现个性化商品推荐的完整系统。
主要研究内容:
1. 协同过滤算法研究: 深入研究基于用户的协同过滤(User-Based CF)和基于物品的协同过滤(Item-Based CF)的核心原理、相似度计算方法(如余弦相似度、皮尔逊相关系数)以及评分预测策略。
2. 系统需求分析与总体设计: 明确系统的功能性需求(如用户管理、商品浏览、评分采集、推荐生成)与非功能性需求(如响应速度、可扩展性)。设计系统架构,包括数据层、算法层、应用层和表现层。
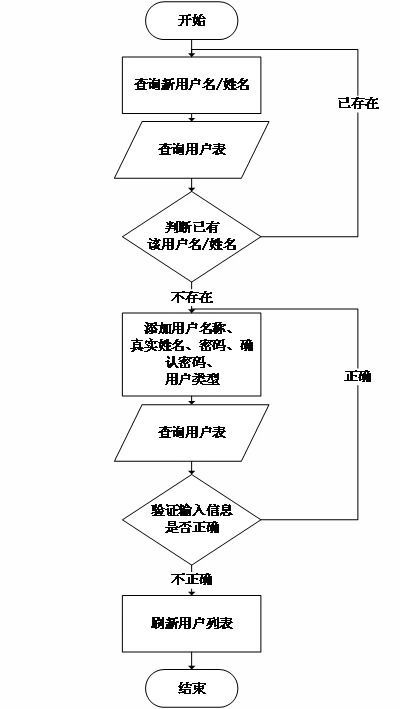
3. 系统详细设计与实现: 完成数据库设计(用户表、商品表、评分记录表等),后端业务逻辑与推荐算法模块的编码实现,以及前端用户交互界面的开发。
4. 系统测试与评估: 采用离线评估指标(如均方根误差RMSE、平均绝对误差MAE)和在线A/B测试等方式,评估推荐算法的准确性和系统的整体性能。
1.3 拟解决的关键问题与技术路线
关键问题:
1. 数据稀疏性与冷启动问题: 新用户或新商品缺乏历史交互数据,导致算法失效。
2. 算法效率与可扩展性: 用户和商品规模巨大时,传统协同过滤计算复杂度高。
3. 推荐结果的多样性与新颖性平衡。
技术路线:
1. 技术栈选择: 采用Java作为主要开发语言,Spring Boot作为后端框架,MySQL作为关系型数据库,Redis作为缓存数据库以提升性能,Vue.js或Thymeleaf作为前端技术。
2. 算法优化: 针对数据稀疏性,可引入混合推荐策略(如结合基于内容的推荐);针对冷启动,利用用户注册信息或商品属性进行辅助。使用矩阵分解技术(如SVD)或采用Spark MLlib等分布式计算框架处理大规模数据,提升效率。
3. 系统集成: 遵循模块化设计原则,将数据采集、预处理、模型训练、在线推荐等服务进行解耦,通过RESTful API进行通信,保证系统的可维护性和可扩展性。
1.4 预期成果与进度安排
预期成果:
1. 一份完整的毕业设计论文。
2. 一个可运行的、具备核心推荐功能的商品推荐系统源码。
3. 系统设计文档、测试报告等配套材料。
进度安排:
- 第1-2周:文献调研,完成开题报告。
- 第3-5周:需求分析,系统总体设计与数据库设计。
- 第6-10周:算法模块实现与核心功能开发。
- 第11-13周:系统集成、测试与优化。
- 第14-15周:论文撰写与修改。
- 第16周:准备答辩。
二、系统源码核心模块概述
系统将采用典型的B/S架构和MVC设计模式进行开发。
2.1 后端模块 (Java/Spring Boot)
1. 实体层 (Entity): 定义与数据库表映射的Java Bean,如User, Product, Rating。
2. 数据访问层 (Repository): 使用Spring Data JPA或MyBatis-Plus进行数据库操作。
3. 业务逻辑层 (Service): 核心推荐算法在此实现。
`java
// 伪代码示例:基于用户的协同过滤推荐服务接口
public interface RecommendService {
/**
- 为目标用户生成Top-N商品推荐列表
- @param userId 目标用户ID
- @param n 推荐列表长度
- @return 推荐商品ID列表
*/
List
/**
- 计算用户相似度矩阵 (可预计算并缓存至Redis)
*/
Map
}
`
- 控制层 (Controller): 提供REST API,如
GET /api/recommend/{userId}。 - 算法包 (Algorithm): 包含独立的相似度计算类、预测评分类等。
2.2 前端模块
- 负责用户界面展示,包括用户登录/注册、商品列表展示、评分提交、个人推荐结果展示等页面。
- 可通过Ajax调用后端API获取实时推荐结果。
2.3 数据库设计
- 用户表 (user):
user_id,username,password,gender,age等。 - 商品表 (product):
product_id,name,category,price,description等。 - 评分表 (rating):
id,user<em>id,product</em>id,score,timestamp。
三、论文结构建议
第一章 绪论
- 研究背景与意义
- 国内外研究现状
- 主要研究内容与目标
- 论文组织结构
第二章 相关技术与理论
- 推荐系统概述
- 协同过滤算法原理详解(用户/物品基于)
- 相似度度量方法
- 相关技术框架介绍(Spring Boot, MySQL等)
第三章 系统需求分析与设计
- 系统可行性分析
- 功能性需求分析
- 非功能性需求分析
- 系统总体架构设计
- 数据库设计
第四章 系统详细设计与实现
- 开发环境与工具
- 关键模块详细设计(用户模块、商品模块、推荐引擎模块)
- 协同过滤算法的实现与优化细节
- 系统界面展示
第五章 系统测试与评估
- 测试环境
- 功能测试用例与结果
- 推荐算法性能评估(离线实验设计、评估指标分析)
- 系统性能测试
第六章 与展望
- 工作
- 系统存在的不足
- 未来改进方向
四、计算机系统集成要点
本项目本身即是一个小型的计算机系统集成实践,涉及以下层面的集成:
- 软件层次集成: 将Java后端业务系统、推荐算法模块、前端展示页面、数据库管理系统进行有效整合,形成一个有机整体。
- 数据集成: 实现业务数据(用户、商品)与行为数据(评分)的统一存储与管理,为算法提供高质量数据源。
- 技术集成: 综合运用了Java编程技术、Web开发技术、数据库技术、推荐算法(数据挖掘)技术,体现了多技术融合的能力。
- 功能集成: 系统集成了用户管理、商品管理、评分交互、智能推荐等多种功能,提供了完整的业务流程。
在论文和答辩中,可以强调如何通过清晰的模块划分、标准的接口设计(如API)、统一的数据规范,将这些独立的组件和技术平滑地集成为一个稳定、可用的推荐系统,这正是系统集成思想的核心体现。
如若转载,请注明出处:http://www.jiadenakeji.com/product/5.html
更新时间:2026-05-10 17:33:41